Ejemplos y aplicaciones
Durante esta lección, exploraremos algunos ejemplos de algoritmos variacionales y cómo aplicarlos:
- Cómo escribir un algoritmo variacional personalizado
- Cómo aplicar un algoritmo variacional para encontrar valores propios mínimos
- Cómo utilizar algoritmos variacionales para resolver casos de uso en aplicaciones
Ten en cuenta que el marco de patrones de Qiskit puede aplicarse a todos los problemas que presentamos aquí. Sin embargo, para evitar repetición, solo mencionaremos explícitamente los pasos del marco en un caso de ejemplo, ejecutado en hardware real.
Definiciones de problemas
Imagina que queremos usar un algoritmo variacional para encontrar el valor propio del siguiente observable:
Este observable tiene los siguientes valores propios:
Y los siguientes estados propios:
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-ibm-runtime rustworkx scipy
from qiskit.quantum_info import SparsePauliOp
observable_1 = SparsePauliOp.from_list([("II", 2), ("XX", -2), ("YY", 3), ("ZZ", -3)])
VQE personalizado
Primero exploraremos cómo construir una instancia de VQE manualmente para encontrar el valor propio más bajo de . Esto incorporará una variedad de técnicas que hemos visto a lo largo de este curso.
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return cost
from qiskit.circuit.library.n_local import n_local
from qiskit import QuantumCircuit
import numpy as np
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
variational_form = n_local(
num_qubits=2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
raw_ansatz = reference_circuit.compose(variational_form)
raw_ansatz.decompose().draw("mpl")
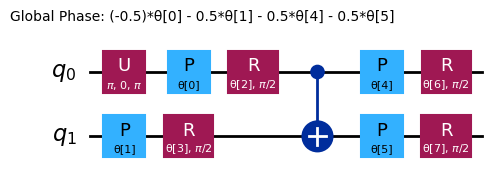
Comenzaremos depurando en simuladores locales.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Ahora establecemos un conjunto inicial de parámetros:
x0 = np.ones(raw_ansatz.num_parameters)
print(x0)
[1. 1. 1. 1. 1. 1. 1. 1.]
Podemos minimizar esta función de costo para calcular los parámetros óptimos
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe,
x0,
args=(raw_ansatz, observable_1, estimator),
method="COBYLA",
options={"maxiter": 1000, "disp": True},
)
end_time = time.time()
execution_time = end_time - start_time
Return from COBYLA because the trust region radius reaches its lower bound.
Number of function values = 103 Least value of F = -5.999999998357189
The corresponding X is:
[2.27483579e+00 8.37593091e-01 1.57080508e+00 5.82932911e-06
2.49973063e+00 6.41884255e-01 6.33686904e-01 6.33688223e-01]
result
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -5.999999998357189
x: [ 2.275e+00 8.376e-01 1.571e+00 5.829e-06 2.500e+00
6.419e-01 6.337e-01 6.337e-01]
nfev: 103
maxcv: 0.0
Como este problema de ejemplo solo utiliza dos qubits, podemos verificarlo usando el solucionador de álgebra lineal de NumPy.
from numpy.linalg import eigvalsh
solution_eigenvalue = min(eigvalsh(observable_1.to_matrix()))
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((result.fun - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Number of iterations: 103
Time (s): 0.4394676685333252
Percent error: 2.74e-08
Como puedes ver, el resultado es extremadamente cercano al ideal.
Experimentando para mejorar la velocidad y la precisión
Agregar estado de referencia
En el ejemplo anterior no hemos utilizado ningún operador de referencia . Ahora pensemos en cómo puede obtenerse el estado propio ideal . Considera el siguiente circuito.
from qiskit import QuantumCircuit
ideal_qc = QuantumCircuit(2)
ideal_qc.h(0)
ideal_qc.cx(0, 1)
ideal_qc.draw("mpl")

Podemos verificar rápidamente que este circuito nos da el estado deseado.
from qiskit.quantum_info import Statevector
Statevector(ideal_qc)
Statevector([0.70710678+0.j, 0. +0.j, 0. +0.j,
0.70710678+0.j],
dims=(2, 2))
Ahora que hemos visto cómo luce un circuito que prepara el estado solución, parece razonable usar una puerta Hadamard como circuito de referencia, de modo que el ansatz completo sea:
reference = QuantumCircuit(2)
reference.h(0)
reference.cx(0, 1)
# Include barrier to separate reference from variational form
reference.barrier()
ref_ansatz = variational_form.decompose().compose(reference, front=True)
ref_ansatz.draw("mpl")
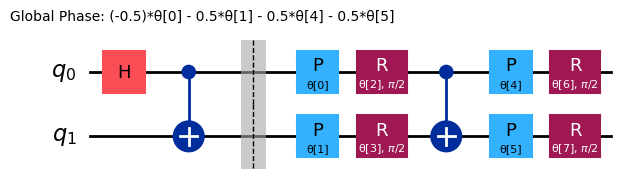
Para este nuevo circuito, la solución ideal podría alcanzarse con todos los parámetros en , lo que confirma que la elección del circuito de referencia es razonable.
Ahora comparemos el número de evaluaciones de la función de costo, las iteraciones del optimizador y el tiempo empleado con los del intento anterior.
import time
start_time = time.time()
ref_result = minimize(
cost_func_vqe, x0, args=(ref_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
Usando nuestros parámetros óptimos para calcular el valor propio mínimo:
experimental_min_eigenvalue_ref = cost_func_vqe(
ref_result.x, ref_ansatz, observable_1, estimator
)
print(experimental_min_eigenvalue_ref)
-5.999999996759607
print("ADDED REFERENCE STATE:")
print(f"""Number of iterations: {ref_result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((experimental_min_eigenvalue_ref - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
ADDED REFERENCE STATE:
Number of iterations: 127
Time (s): 0.5620882511138916
Percent error: 5.40e-08
Dependiendo de tu sistema específico, esto puede o no resultar en una mejora de velocidad o precisión en este ejemplo de escala muy pequeña. Lo importante es que partir de estados de referencia motivados físicamente se vuelve cada vez más relevante para mejorar la velocidad y la precisión a medida que los problemas escalan.
Cambiar el punto inicial
Ahora que hemos visto el efecto de agregar el estado de referencia, veamos qué ocurre cuando elegimos distintos puntos iniciales . En particular, usaremos y .
Recuerda que, como se discutió cuando se introdujo el estado de referencia, la solución ideal se encontraría cuando todos los parámetros sean , por lo que el primer punto inicial debería dar menos evaluaciones.
import time
start_time = time.time()
x0 = [0, 0, 0, 0, 6, 0, 0, 0]
x0_1_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 1:")
print(f"""Number of iterations: {x0_1_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 1:
Number of iterations: 108
Time (s): 0.4492197036743164
Ajustando el punto inicial a :
import time
start_time = time.time()
x0 = 6 * np.ones(raw_ansatz.num_parameters)
x0_2_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 2:")
print(f"""Number of iterations: {x0_2_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 2:
Number of iterations: 107
Time (s): 0.40889453887939453
Al experimentar con distintos puntos iniciales, es posible que logres una convergencia más rápida y con menos evaluaciones de la función.
Experimentar con distintos optimizadores
Podemos ajustar el optimizador usando el argumento method de minimize de SciPy, con más opciones disponibles aquí. Originalmente usamos un minimizador con restricciones (COBYLA). En este ejemplo, exploraremos el uso de un minimizador sin restricciones (BFGS) en su lugar.
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="BFGS"
)
end_time = time.time()
execution_time = end_time - start_time
print("CHANGED TO BFGS OPTIMIZER:")
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
CHANGED TO BFGS OPTIMIZER:
Number of iterations: 117
Time (s): 0.31656408309936523
Ejemplo de VQD
Aquí implementamos el marco de patrones de Qiskit de forma explícita.
Paso 1: Mapear las entradas clásicas a un problema cuántico
En lugar de buscar solo el autovalor más bajo de nuestros observables, buscaremos los (donde ).
Recuerda que las funciones de costo de VQD son:
Esto es particularmente importante porque un vector (en este caso ) debe pasarse como argumento al definir el objeto VQD.
Además, en la implementación de VQD de Qiskit, en lugar de considerar los observables efectivos descritos en el cuaderno anterior, las fidelidades se calculan directamente mediante el algoritmo ComputeUncompute, que se apoya en una primitiva Sampler para muestrear la probabilidad de obtener para el circuito
. Esto funciona precisamente porque dicha probabilidad es
ansatz = n_local(
num_qubits=2,
rotation_blocks=["ry", "rz"],
entanglement_blocks="cz",
# entanglement="linear",
reps=1,
)
ansatz.decompose().draw("mpl")
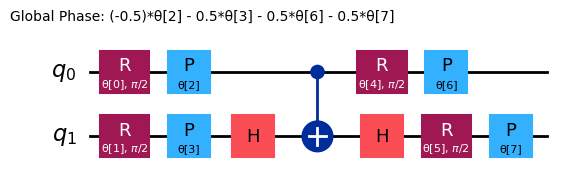
Comencemos examinando el siguiente observable:
Este observable tiene los siguientes autovalores:
Y los autoestados:
from qiskit.quantum_info import SparsePauliOp
observable_2 = SparsePauliOp.from_list([("II", 2), ("XX", -3), ("YY", 2), ("ZZ", -4)])
Usaremos la siguiente función para calcular la penalización por solapamiento. Ten en cuenta que esto sigue siendo parte del mapeo del problema a circuitos cuánticos. Sin embargo, como se discutió en la lección anterior, esta función calcula el solapamiento entre el circuito variacional actual y el circuito optimizado de un estado previo de menor energía/costo. El nuevo circuito que se genera también debe ser transpilado para ejecutarse en hardware real. Ya hemos visto esta función antes, usada en un simulador. Aquí debemos considerar ya la transpilación y la optimización relacionada para cuando usemos un backend real, de ahí las líneas en torno a if realbackend == 1. Esto mezcla un poco el paso 2, pero lo señalaremos explícitamente más adelante.
import numpy as np
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
def calculate_overlaps(
ansatz, prev_circuits, parameters, sampler, realbackend, backend
):
def create_fidelity_circuit(circuit_1, circuit_2):
if len(circuit_1.clbits) > 0:
circuit_1.remove_final_measurements()
if len(circuit_2.clbits) > 0:
circuit_2.remove_final_measurements()
circuit = circuit_1.compose(circuit_2.inverse())
circuit.measure_all()
return circuit
overlaps = []
for prev_circuit in prev_circuits:
fidelity_circuit = create_fidelity_circuit(ansatz, prev_circuit)
if realbackend == 1:
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
fidelity_circuit = pm.run(fidelity_circuit)
sampler_job = sampler.run([(fidelity_circuit, parameters)])
meas_data = sampler_job.result()[0].data.meas
counts_0 = meas_data.get_int_counts().get(0, 0)
shots = meas_data.num_shots
overlap = counts_0 / shots
overlaps.append(overlap)
return np.array(overlaps)
Ahora añadimos la función de costo de VQD. Ten en cuenta que, en comparación con la lección anterior, ahora tenemos dos argumentos adicionales (realbackend y backend) para facilitar la transpilación cuando usamos backends reales.
def cost_func_vqd(
parameters,
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
hamiltonian,
realbackend,
backend,
):
estimator_job = estimator.run([(ansatz, hamiltonian, [parameters])])
total_cost = 0
if step > 1:
overlaps = calculate_overlaps(
ansatz, prev_states, parameters, sampler, realbackend, backend
)
total_cost = np.sum(
[np.real(betas[state] * overlap) for state, overlap in enumerate(overlaps)]
)
estimator_result = estimator_job.result()[0]
value = estimator_result.data.evs[0] + total_cost
return value
Una vez más, usaremos simuladores para depurar y luego pasaremos al hardware real.
from qiskit.primitives import StatevectorSampler
from qiskit.primitives import StatevectorEstimator
sampler = StatevectorSampler(default_shots=4092)
estimator = StatevectorEstimator()
Aquí introducimos el número de estados que deseamos calcular, las penalizaciones y un conjunto de parámetros iniciales, x0.
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = [50, 60, 40]
x0 = np.ones(8)
Ahora probaremos el algoritmo usando simuladores:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"maxiter": 200, "tol": 0.000001},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.9999999999996
x: [ 1.571e+00 1.571e+00 2.519e+00 2.100e+00 1.242e+00
6.935e-01 2.298e+00 1.991e+00]
nfev: 151
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 3.698974255258432
x: [ 1.269e+00 1.109e+00 1.080e+00 1.200e+00 1.094e+00
1.163e+00 9.752e-01 9.519e-01]
nfev: 103
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 4.731320121938101
x: [ 1.533e+00 2.451e+00 2.526e+00 2.406e+00 1.968e+00
2.105e+00 8.537e-01 8.442e-01]
nfev: 110
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 7.008239313655201
x: [ 4.150e+00 2.120e+00 3.495e+00 7.262e-01 1.953e+00
-1.982e-01 3.263e-01 2.563e+00]
nfev: 126
maxcv: 0.0
eigenvalues
[np.float64(-6.9999999999996),
np.float64(3.698974255258432),
np.float64(4.731320121938101),
np.float64(7.008239313655201)]
Estos resultados son bastante cercanos a los esperados, salvo el error de aproximación y la fase global. Podríamos ajustar la tolerancia del optimizador clásico y/o las penalizaciones por solapamiento de vectores de estado para obtener valores más precisos.
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 5.71e-14
Percent error: 2.33e-01
Percent error: 5.37e-02
Percent error: 1.18e-03
Cambiar las betas
Como se menciónó en la lección anterior, los valores de deben ser mayores que la diferencia entre autovalores. Veamos qué ocurre cuando no se cumple esa condición con :
con autovalores
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = np.ones(3)
x0 = np.zeros(8)
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.01, "maxiter": 200},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.999916534745094
x: [ 1.568e+00 -1.569e+00 1.385e-01 1.398e-01 -7.972e-01
7.835e-01 -2.375e-01 4.539e-02]
nfev: 125
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.515139929812874
x: [-5.317e-04 -2.514e-03 1.016e+00 9.998e-01 3.890e-04
1.772e-04 1.568e-04 8.497e-04]
nfev: 35
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.509948114293115
x: [-3.796e-03 8.853e-03 3.015e-04 9.997e-01 6.271e-04
-2.554e-03 1.017e-04 2.766e-04]
nfev: 37
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 0.4914672235935682
x: [-7.178e-03 -8.652e-03 1.125e+00 -5.428e-02 -1.586e-03
2.031e-03 -3.462e-03 5.734e-03]
nfev: 35
maxcv: 0.0
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 1.19e-05
Percent error: 1.51e+00
Percent error: 1.10e+00
Percent error: 9.30e-01
Esta vez, el optimizador devuelve el mismo estado como solución propuesta para todos los autoestados, lo cual es claramente incorrecto. Esto ocurre porque las betas eran demasiado pequeñas para penalizar el autoestado mínimo en las funciones de costo sucesivas. Por lo tanto, no quedó excluido del espacio de búsqueda efectivo en iteraciones posteriores del algoritmo y siempre fue elegido como la mejor solución posible.
Recomendamos experimentar con los valores de y asegurarte de que sean mayores que la diferencia entre autovalores.
Paso 2: Optimizar el problema para la ejecución cuántica
Para ejecutar esto en hardware real, debemos optimizar los circuitos cuánticos para el ordenador cuántico que hayamos elegido. Para nuestros propósitos aquí, simplemente usaremos el backend menos ocupado.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or use a specific backend
# backend = service.backend("ibm_brisbane")
print(backend)
<IBMBackend('ibm_brisbane')>
Transpilaremos nuestro circuito usando un gestor de pases preconfigurado con nivel de optimización 3.
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = observable_2.apply_layout(layout=isa_ansatz.layout)
Paso 3: Ejecutar usando las primitivas de Qiskit
Asegurándonos de restablecer las betas a valores suficientemente altos, ya podemos ejecutar nuestro cálculo en hardware cuántico real.
# Estimated compute resource usage: 25 minutes.
# Benchmarked at 24 min, 30 sec on an Eagle r3 processor on 5-30-24
k = 2
betas = [30, 50, 80]
x0 = np.zeros(8)
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(isa_ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"maxiter": 200},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Paso 4: Post-procesar, devolver el resultado en formato clásico
Nuestra salida es estructuralmente similar a lo discutido en lecciones y ejemplos anteriores. Pero hay algo problemático en los resultados anteriores, de lo cual podemos extraer un mensaje de advertencia para el contexto de los estados excitados. Para limitar el tiempo de cómputo utilizado en este ejemplo de aprendizaje, establecimos un número máximo de iteraciones para el optimizador clásico que posiblemente era demasiado bajo: 200 iteraciones. Un cálculo anterior en un simulador no logró converger en 200 iteraciones. Aquí el nuestro sí convergió... ¿pero con qué tolerancia? No hemos especificado ninguna tolerancia para que COBYLA se considere "convergido". Un vistazo al valor de la función y la comparación con ejecuciones previas nos indica que COBYLA no estaba cerca de converger a la precisión que requerimos.
Hay otro problema: ¡la energía del primer estado excitado parece ser menor que la del estado fundamental! Intenta explicar cómo podría ocurrir esto. Pista: está relacionado con el punto de convergencia que acabamos de mencionar. Este comportamiento se explica en detalle más adelante, después de aplicar VQD a la molécula H2.
Química cuántica: solver de estado fundamental y estados excitados
Nuestro objetivo es minimizar el valor esperado del observable que representa la energía (hamiltoniano ):
from qiskit.quantum_info import SparsePauliOp
from qiskit.circuit.library import efficient_su2
H2_op = SparsePauliOp.from_list(
[
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156),
]
)
chem_ansatz = efficient_su2(H2_op.num_qubits)
chem_ansatz.decompose().draw("mpl")
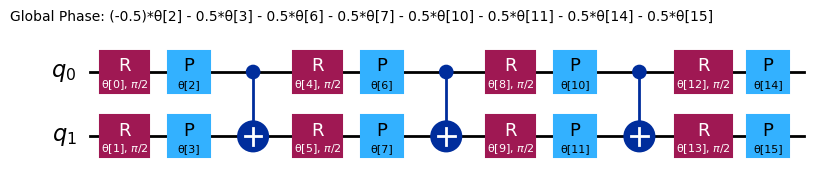
from qiskit import QuantumCircuit
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
Ahora establecemos un conjunto inicial de parámetros:
import numpy as np
x0 = np.ones(chem_ansatz.num_parameters)
Podemos minimizar esta función de costo para calcular los parámetros óptimos, y podemos verificar nuestro código primero usando un simulador local.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(chem_ansatz, H2_op, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
result
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.857275029048451
x: [ 7.326e-01 1.354e+00 ... 1.040e+00 1.508e+00]
nfev: 242
maxcv: 0.0
El valor mínimo de la función de costo (-1.857...) es la energía del estado fundamental de la molécula H2, en unidades de hartrees.
Estados excitados
También podemos aprovechar VQD para resolver estados en total (el estado fundamental y el primer estado excitado).
from qiskit.quantum_info import SparsePauliOp
import numpy as np
k = 2
betas = [33, 33]
# x0 = np.zeros(ansatz.num_parameters)
x0 = [
1.164e00,
-2.438e-01,
9.358e-04,
6.745e-02,
1.990e00,
9.810e-02,
6.154e-01,
5.454e-01,
]
Añadiremos el cálculo de solapamiento:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
H2_op,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 2000},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.8572671093941977
x: [ 1.164e+00 -2.437e-01 2.118e-03 6.448e-02 1.990e+00
9.870e-02 6.167e-01 5.476e-01]
nfev: 58
maxcv: 0.0
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.0322873777662176
x: [ 3.205e+00 1.502e+00 1.699e+00 -1.107e-02 3.086e+00
1.530e+00 4.445e-02 7.013e-02]
nfev: 99
maxcv: 0.0
eigenvalues
[-1.8572671093941977, -1.0322873777662176]
Hardware real y una advertencia final
Para ejecutar esto en hardware real, debemos optimizar los circuitos cuánticos para el computador cuántico de nuestra elección. Para nuestros propósitos aquí, simplemente usaremos el backend menos ocupado.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
Usaremos un pass manager preconfigurado para la transpilación, y optimizaremos al máximo nuestro circuito usando el nivel de optimización 3.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = H2_op.apply_layout(layout=isa_ansatz.layout)
Dado que VQD es altamente iterativo, llevaremos a cabo todos los pasos dentro de una sesión de Runtime, de modo que nuestros trabajos solo se pondrán en cola al principio, y no entre cada actualización de parámetros. Nada más cambia en la sintaxis de la función de costo o del estimador.
x0 = [
1.306e00,
-2.284e-01,
6.913e-02,
-2.530e-02,
1.849e00,
7.433e-02,
6.366e-01,
5.600e-01,
]
# Estimated hardware usage: 20 min benchmarked on an Eagle r3 processor on 5-30-24
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=4096)
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(
isa_ansatz.assign_parameters(real_prev_opt_parameters)
)
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 300},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
La energía del estado fundamental obtenida (-1.83 hartrees) no se aleja demasiado del valor correcto (-1.85 hartrees). Sin embargo, la energía del estado excitado está bastante lejos. Esto es similar al comportamiento erróneo que vimos antes en esta lección. La energía reportada para el estado excitado es casi la misma que la del estado fundamental. En el caso anterior, incluso vimos una energía del estado excitado que era menor que la energía del estado fundamental reportada.
No es posible que un cálculo variacional produzca una energía inferior a la verdadera energía del estado fundamental. En el caso anterior, la energía del estado fundamental que obtuvimos no era muy cercana al verdadero estado fundamental. Como no obtuvimos la verdadera energía del estado fundamental en ese caso, no hay contradicción. En el caso presente, la energía del estado fundamental estuvo bastante cerca del valor correcto, y aun así la energía del estado excitado parece extrañamente cercana a ese mismo valor.
Para entender mejor cómo ocurrió esto, recuerda que la forma en que encontramos un estado excitado es exigiendo que el estado variacional sea ortogonal al estado fundamental (usando los circuitos de solapamiento y los términos de penalización). Si no logramos obtener una energía precisa del estado fundamental (o nos desviamos unos pocos porcentajes), ¡también fallamos en obtener un vector preciso del estado fundamental! Entonces, cuando exigimos que el estado excitado sea ortogonal al primer estado que encontramos, no estábamos imponiendo ortogonalidad con el verdadero estado fundamental, sino con alguna aproximación de él (a veces una aproximación bastante pobre). Por tanto, el estado excitado no se vio forzado a ser ortogonal al verdadero estado fundamental, y nuestras estimaciones de energía para los estados excitados resultaron muy cercanas a la energía del estado fundamental.
Esto siempre será una preocupación en VQD. Pero en principio, puede corregirse aumentando el número máximo de iteraciones del optimizador clásico, imponiendo una tolerancia más baja para el optimizador clásico y, posiblemente, también probando un ansatz diferente si habitualmente no alcanzamos el verdadero estado fundamental. Como hemos visto, también puede ser necesario modificar las penalizaciones de solapamiento (betas). Pero eso es realmente un problema separado. Ninguna penalización por solapamiento te mantendrá alejado del verdadero estado fundamental si no has encontrado una buena estimación del verdadero estado fundamental para el circuito de solapamiento.
Optimización: Max-Cut
El problema de corte máximo (Max-Cut) es un problema de optimización combinatoria que consiste en dividir los vértices de un grafo en dos conjuntos disjuntos de manera que se maximice el número de aristas entre ambos conjuntos. Más formalmente, dado un grafo no dirigido , donde es el conjunto de vértices y el conjunto de aristas, el problema Max-Cut pide particionar los vértices en dos subconjuntos disjuntos, y , de modo que se maximice el número de aristas con un extremo en y el otro en .
Podemos aplicar Max-Cut para resolver una gran variedad de problemas, como agrupamiento, diseño de redes y transiciones de fase. Comenzaremos creando un grafo del problema:
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)

Este problema puede expresarse como un problema de optimización binaria. Para cada nodo , donde es el número de nodos del grafo (en este caso ), consideraremos la variable binaria . Esta variable tomará el valor si el nodo pertenece al grupo que llamaremos , y si pertenece al otro grupo, que llamaremos . También denotaremos como (elemento de la matriz de adyacencia ) el peso de la arista que va del nodo al nodo . Como el grafo es no dirigido, . Así podemos formular nuestro problema como la maximización de la siguiente función de costo:
Para resolver este problema con una computadora cuántica, vamos a expresar la función de costo como el valor esperado de un observable. Sin embargo, los observables que Qiskit admite de forma nativa consisten en operadores de Pauli, que tienen valores propios y en lugar de y . Por eso realizaremos el siguiente cambio de variable:
Donde . Podemos usar la matriz de adyacencia para acceder cómodamente a los pesos de todas las aristas, lo que utilizaremos para obtener nuestra función de costo:
Esto implica que:
Por lo tanto, la nueva función de costo que queremos maximizar es:
Además, la tendencia natural de una computadora cuántica es encontrar mínimos (generalmente la energía más baja) en lugar de máximos, por lo que en vez de maximizar vamos a minimizar:
Ahora que tenemos una función de costo a minimizar cuyas variables pueden tomar los valores y , podemos establecer la siguiente analogía con el operador de Pauli :
En otras palabras, la variable será equivalente a una compuerta actuando sobre el qubit . Además:
Entonces el observable que vamos a considerar es:
al que habrá que sumar el término independiente posteriormente:
El operador es una combinación lineal de términos con operadores Z en los nodos conectados por una arista (recuerda que el qubit 0 está en el extremo derecho): . Una vez construido el operador, el ansatz para el algoritmo QAOA puede construirse fácilmente usando el circuito QAOAAnsatz de la biblioteca de circuitos de Qiskit.
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
max_hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
max_ansatz = QAOAAnsatz(max_hamiltonian, reps=2)
# Draw
max_ansatz.decompose(reps=3).draw("mpl")

# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")
Offset: -2.5
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Ahora establecemos un conjunto inicial de parámetros aleatorios:
import numpy as np
x0 = 2 * np.pi * np.random.rand(max_ansatz.num_parameters)
print(x0)
[6.0252949 0.58448176 2.15785731 1.13646074]
Se puede usar cualquier optimizador clásico para minimizar la función de costo. En un sistema cuántico real, suele funcionar mejor un optimizador diseñado para paisajes de función de costo no suaves. Aquí usamos la rutina COBYLA de SciPy a través de la función minimize.
Dado que ejecutamos iterativamente muchas llamadas a Runtime, utilizamos una sesión para ejecutar todas las llamadas dentro de un único bloque. Además, en QAOA la solución está codificada en la distribución de salida del circuito ansatz vinculado con los parámetros óptimos obtenidos de la minimización. Por ello necesitaremos una primitiva Sampler, que instanciaremos con la misma sesión. Luego ejecutamos nuestra rutina de minimización:
result = minimize(
cost_func, x0, args=(max_ansatz, max_hamiltonian, estimator), method="COBYLA"
)
print(result)
message: Optimization terminated successfully.
success: True
status: 1
fun: -2.585287311689236
x: [ 7.332e+00 3.904e-01 2.045e+00 1.028e+00]
nfev: 80
maxcv: 0.0
El vector de solución de ángulos de parámetros (x), al introducirlo en el circuito ansatz, produce la partición del grafo que estábamos buscando.
eigenvalue = cost_func(result.x, max_ansatz, max_hamiltonian, estimator)
print(f"""Eigenvalue: {eigenvalue}""")
print(f"""Max-Cut Objective: {eigenvalue + offset}""")
Eigenvalue: -2.585287311689236
Max-Cut Objective: -5.085287311689235
from qiskit.result import QuasiDistribution
from qiskit.primitives import StatevectorSampler
sampler = StatevectorSampler()
# Assign solution parameters to ansatz
qc = max_ansatz.assign_parameters(result.x)
# Add measurements to our circuit
qc.measure_all()
# Sample ansatz at optimal parameters
# samp_dist = sampler.run(qc).result().quasi_dists[0]
shots = 1024
job = sampler.run([qc], shots=shots)
qc.decompose().draw("mpl")

data_pub = job.result()[0].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
probabilities = quasi_dist
# Close the session since we are now done with it
# session.close()
from qiskit.visualization import plot_distribution
plot_distribution(counts)

binary_string = max(counts.items(), key=lambda kv: kv[1])[0]
x = np.asarray([int(y) for y in reversed(list(binary_string))])
colors = ["r" if x[i] == 0 else "c" for i in range(n)]
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color=colors
)

Resumen
Con esta lección has aprendido:
- Cómo escribir un algoritmo variacional personalizado
- Cómo aplicar un algoritmo variacional para encontrar valores propios mínimos
- Cómo utilizar algoritmos variacionales para resolver casos de uso en aplicaciones concretas
¡Continúa con la lección final para realizar tu evaluación y obtener tu insignia!