Codificación de datos
Introducción y notación
Para usar un algoritmo cuántico, los datos clásicos deben introducirse de alguna forma en un circuito cuántico. Esto se conoce habitualmente como codificación de datos, aunque también se llama carga de datos. Recuerda de lecciones anteriores el concepto de mapeo de características: una transformación de las características de los datos de un espacio a otro. Transferir datos clásicos a un ordenador cuántico es en sí mismo un tipo de mapeo y podría denominarse mapeo de características. En la práctica, los mapeos de características integrados en Qiskit (como z_feature_map y zz_feature_map) suelen incluir capas de rotación y capas de entrelazamiento que extienden el estado a muchas dimensiones en el espacio de Hilbert. Este proceso de codificación es una parte fundamental de los algoritmos de aprendizaje automático cuántico y afecta directamente a sus capacidades computacionales.
Algunas de las técnicas de codificación que se presentan a continuación pueden simularse eficientemente de forma clásica; esto es especialmente evidente en métodos de codificación que producen estados producto (es decir, que no entrelazan qubits). Y recuerda que la utilidad cuántica es más probable allá donde la complejidad cuántica del conjunto de datos encaje bien con el método de codificación. Por eso es muy probable que acabes escribiendo tus propios circuitos de codificación. Aquí mostramos una amplia variedad de estrategias de codificación posibles simplemente para que puedas compararlas y ver qué es factible. Hay algunas afirmaciones muy generales que pueden hacerse sobre la utilidad de las técnicas de codificación. Por ejemplo, efficient_su2 (ver más abajo) con un esquema de entrelazamiento completo es mucho más probable que capture características cuánticas de los datos que los métodos que producen estados producto (como z_feature_map). Pero esto no significa que efficient_su2 sea suficiente, ni que esté lo bastante bien ajustado a tu conjunto de datos, para producir una aceleración cuántica. Eso requiere una consideración cuidadosa de la estructura de los datos que se modelan o clasifican. También hay un equilibrio con la profundidad del circuito, ya que muchos mapeos de características que entrelazan completamente los qubits en un circuito producen circuitos muy profundos, demasiado profundos para obtener resultados útiles en los ordenadores cuánticos actuales.
Notación
Un conjunto de datos es un conjunto de vectores de datos: , donde cada vector tiene dimensiones, es decir, . Esto podría extenderse a características de datos complejas. En esta lección usaremos en ocasiones estas notaciones para el conjunto completo y para sus elementos específicos como . Sin embargo, la mayor parte del tiempo nos referiremos a la carga de un único vector de nuestro conjunto de datos a la vez, y con frecuencia haremos referencia simplemente a un único vector de características como .
Además, es habitual usar el símbolo para referirse al mapeo de características del vector de datos . En computación cuántica en concreto, es común referirse a los mapeos mediante , una notación que refuerza la naturaleza unitaria de estas operaciones. Se podría usar el mismo símbolo para ambos; los dos son mapeos de características. A lo largo de este curso tendemos a usar:
- cuando hablamos de mapeos de características en aprendizaje automático en general, y
- cuando hablamos de implementaciones en circuito de los mapeos de características.
Normalización y pérdida de información
En el aprendizaje automático clásico, las características de los datos de entrenamiento se "normalizan" o reescalan con frecuencia, lo que suele mejorar el rendimiento del modelo. Una forma habitual de hacerlo es la normalización mín-máx o la estandarización. En la normalización mín-máx, las columnas de características de la matriz de datos (digamos, la característica ) se normalizan:
donde min y max se refieren al mínimo y máximo de la característica sobre los vectores de datos del conjunto . Todos los valores de las características caen entonces en el intervalo unitario: para todo , .
La normalización es también un concepto fundamental en mecánica cuántica y computación cuántica, aunque es ligeramente diferente a la normalización mín-máx. La normalización en mecánica cuántica exige que la longitud (en el contexto de la computación cuántica, la norma-2) de un vector de estado sea igual a la unidad: , lo que garantiza que las probabilidades de medición sumen 1. El estado se normaliza dividiéndolo por la norma-2; es decir, reescalando
En computación cuántica y mecánica cuántica, esta no es una normalización que la gente imponga sobre los datos, sino una propiedad fundamental de los estados cuánticos. Dependiendo de tu esquema de codificación, esta restricción puede afectar a cómo se reescalan los datos. Por ejemplo, en la codificación por amplitud (ver más abajo), el vector de datos se normaliza como exige la mecánica cuántica, y esto afecta al escalado de los datos que se codifican. En la codificación por fase, se recomienda reescalar los valores de las características como para evitar pérdida de información debida al efecto módulo- de codificar en un ángulo de fase de qubit[1,2].
Métodos de codificación
En las siguientes secciones haremos referencia a un pequeño conjunto de datos clásico de ejemplo compuesto por vectores de datos, cada uno con características:
Con la notación introducida anteriormente, podríamos decir que la característica del vector de datos de nuestro conjunto es , por ejemplo.
Codificación en base
La codificación en base codifica una cadena clásica de bits en un estado base computacional de un sistema de qubits. Tomemos por ejemplo Esto puede representarse como una cadena de bits como , y mediante un sistema de qubits como el estado cuántico . De forma más general, para una cadena de bits: , el estado de qubits correspondiente es con para . Hay que tener en cuenta que esto es solo para una única característica.
La codificación en base en computación cuántica representa cada bit clásico como un qubit separado, mapeando la representación binaria de los datos directamente sobre los estados cuánticos en la base computacional. Cuando es necesario codificar varias características, cada una se convierte primero a su forma binaria y luego se asigna a un grupo distinto de qubits —un grupo por característica— donde cada qubit refleja un bit de la representación binaria de esa característica.
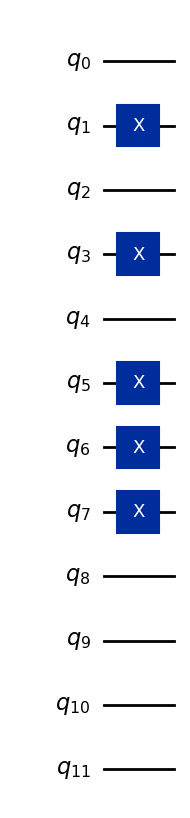
Como ejemplo, vamos a codificar el vector (5, 7, 0).
Supongamos que todas las características se almacenan en cuatro bits (más de lo necesario, pero suficiente para representar cualquier entero de un solo dígito en base 10):
5 → binario 0101
7 → binario 0111
0 → binario 0000
Estas cadenas de bits se asignan a tres conjuntos de cuatro qubits, por lo que el estado base global de 12 qubits es:
Aquí, los primeros cuatro qubits representan la primera característica, los cuatro siguientes la segunda característica, y los cuatro últimos la tercera característica. El código siguiente convierte el vector de datos (5,7,0) en un estado cuántico, y está generalizado para hacer lo mismo con otras características de un solo dígito.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Comprueba tu comprensión
Lee la pregunta a continuación, piensa tu respuesta y luego haz clic en el triángulo para ver la solución.
Escribe código para codificar el primer vector de nuestro conjunto de datos de ejemplo :
usando codificación en base.
Respuesta:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Codificación por amplitud
La codificación por amplitud codifica los datos en las amplitudes de un estado cuántico. Representa un vector de datos clásico normalizado de dimensiones, , como las amplitudes de un estado cuántico de qubits, :
donde es la misma dimensión de los vectores de datos que antes, es el elemento de y es el estado base computacional. Aquí, es una constante de normalización que se determina a partir de los datos que se codifican. Esta es la condición de normalización impuesta por la mecánica cuántica:
En general, esta es una condición distinta a la normalización mín/máx usada para cada característica sobre todos los vectores de datos. La forma exacta de gestionarlo dependerá de tu problema. Pero no hay manera de evitar la condición de normalización de la mecánica cuántica anterior.
En la codificación por amplitud, cada característica de un vector de datos se almacena como la amplitud de un estado cuántico diferente. Como un sistema de qubits proporciona amplitudes, la codificación por amplitud de características requiere qubits.
Como ejemplo, vamos a codificar el primer vector de nuestro conjunto de datos de ejemplo , , usando codificación por amplitud. Al normalizar el vector resultante obtenemos:
y el estado cuántico de 2 qubits resultante sería:
En el ejemplo anterior, el número de características del vector no es una potencia de 2. Cuando no es una potencia de 2, simplemente elegimos un valor para el número de qubits tal que y rellenamos el vector de amplitudes con constantes no informativas (aquí, un cero).
Al igual que en la codificación en base, una vez que calculamos qué estado codificará nuestro conjunto de datos, en Qiskit podemos usar la función initialize para prepararlo:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Una ventaja de la codificación por amplitud es el requisito antes mencionado de solo qubits para la codificación. Sin embargo, los algoritmos posteriores deben operar sobre las amplitudes de un estado cuántico, y los métodos para preparar y medir los estados cuánticos tienden a no ser eficientes.
Comprueba tu comprensión
Lee las preguntas a continuación, piensa tus respuestas y luego haz clic en los triángulos para ver las soluciones.
Escribe el estado normalizado para codificar el siguiente vector (formado por dos vectores de nuestro conjunto de datos de ejemplo):
usando codificación por amplitud.
Respuesta:
Para codificar 6 números necesitaremos tener al menos 6 estados disponibles en cuyas amplitudes podamos codificar. Esto requerirá 3 qubits. Usando un factor de normalización desconocido , podemos escribirlo como:
Nótese que
Entonces, finalmente,
Para el mismo vector de datos escribe código para crear un circuito que cargue estas características de datos usando codificación por amplitud.
Respuesta:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Es posible que tengas que trabajar con vectores de datos muy grandes. Considera el vector
Escribe código para automatizar la normalización y genera un circuito cuántico para la codificación por amplitud.
Respuesta:
Hay muchas respuestas posibles. Aquí hay un código que imprime algunos pasos intermedios:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
¿Ves ventajas de la codificación por amplitud sobre la codificación en base? Si es así, explícalas.
Respuesta:
Puede haber varias respuestas. Una de ellas es que, dado el orden fijo de los estados base, esta codificación por amplitud preserva el orden de los números codificados. Además, con frecuencia se codificará de forma más densa.
Una ventaja de la codificación por amplitud es que solo se necesitan qubits para un vector de datos de dimensiones ( características). Sin embargo, la codificación por amplitud es en general un procedimiento ineficiente que requiere preparación de estados arbitrarios, lo cual es exponencial en el número de puertas CNOT. Dicho de otra forma, la preparación del estado tiene una complejidad temporal polinomial de en el número de dimensiones, donde y es el número de qubits. La codificación por amplitud "ofrece un ahorro exponencial en espacio a costa de un incremento exponencial en tiempo"[3]; sin embargo, es posible reducir la complejidad temporal a en ciertos casos[4]. Para una aceleración cuántica de extremo a extremo, es necesario tener en cuenta la complejidad temporal de la carga de datos.
Codificación por ángulo
La codificación por ángulo es de interés en muchos modelos QML que usan mapeos de características de Pauli, como las máquinas de vectores de soporte cuánticas (QSVM) y los circuitos cuánticos variacionales (VQC), entre otros. La codificación por ángulo está estrechamente relacionada con la codificación por fase y la codificación densa por ángulo, que se presentan más abajo. Aquí usaremos "codificación por ángulo" para referirnos a una rotación en , es decir, una rotación que se aleja del eje conseguida, por ejemplo, mediante una puerta o una puerta [1,3]. En realidad, se pueden codificar datos en cualquier rotación o combinación de rotaciones. Pero es común en la literatura, por lo que la enfatizamos aquí.
Cuando se aplica a un único qubit, la codificación por ángulo imparte una rotación en el eje Y proporcional al valor del dato. Considera la codificación de una única característica (la ) del vector de datos de un conjunto de datos, :
Alternativamente, la codificación por ángulo puede realizarse usando puertas , aunque el estado codificado tendría una fase relativa compleja en comparación con .
La codificación por ángulo difiere de los dos métodos anteriores en varios aspectos. En la codificación por ángulo:
- Cada valor de característica se mapea a un qubit correspondiente, , dejando los qubits en un estado producto.
- Se codifica un valor numérico a la vez, en lugar de un conjunto completo de características de un punto de datos.
- Se requieren qubits para características de datos, donde . Aquí la igualdad suele cumplirse. Veremos cómo es posible que en las próximas secciones.
- El circuito cuántico resultante tiene profundidad constante (típicamente la profundidad es 1 antes de la transpilación).
La profundidad constante del circuito cuántico lo hace especialmente adecuado para el hardware cuántico actual. Una característica adicional de codificar nuestros datos usando (y específicamente, nuestra elección de usar codificación por ángulo en el eje Y) es que crea estados cuánticos de valor real que pueden ser útiles para ciertas aplicaciones. Para la rotación en el eje Y, los datos se mapean con una puerta de rotación en el eje Y con un ángulo real (Qiskit RYGate). Al igual que con la codificación por fase (ver más abajo), recomendamos reescalar los datos de modo que , evitando pérdida de información y otros efectos no deseados.
El siguiente código de Qiskit rota un único qubit desde un estado inicial para codificar un valor de dato .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Definiremos una función para visualizar la acción sobre el vector de estado. Los detalles de la definición de la función no son importantes, pero sí lo es la capacidad de visualizar los vectores de estado y sus cambios.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Eso fue solo una característica de un único vector de datos. Cuando se codifican características en los ángulos de rotación de qubits, digamos para el vector de datos el estado producto codificado tendrá este aspecto:
Notamos que esto es equivalente a
Comprueba tu comprensión
Lee las preguntas a continuación, piensa tus respuestas y luego haz clic en los triángulos para ver las soluciones.
Codifica el vector de datos usando codificación por ángulo, tal como se describió anteriormente.
Respuesta:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Con la codificación por ángulo descrita anteriormente, ¿cuántos qubits se necesitan para codificar 5 características?
Respuesta: 5
Codificación por fase
La codificación por fase es muy similar a la codificación por ángulo descrita anteriormente. El ángulo de fase de un qubit es un ángulo real alrededor del eje desde el eje . Los datos se mapean con una rotación de fase, , donde (ver Qiskit PhaseGate para más información). Se recomienda reescalar los datos de modo que . Esto evita pérdida de información y otros efectos potencialmente no deseados[1,2].
Un qubit se inicializa habitualmente en el estado , que es un autoestado del operador de rotación de fase, lo que significa que el estado del qubit primero necesita rotarse para que la codificación por fase pueda implementarse. Por tanto, tiene sentido inicializar el estado con una puerta Hadamard: . La codificación por fase en un único qubit consiste en imprimir una fase relativa proporcional al valor del dato:
El procedimiento de codificación por fase mapea cada valor de característica a la fase del qubit correspondiente, . En total, la codificación por fase tiene una profundidad de circuito de 2, incluyendo la capa Hadamard, lo que la convierte en un esquema de codificación eficiente. El estado de múltiples qubits codificado por fase ( qubits para características) es un estado producto:
El siguiente código de Qiskit primero prepara el estado inicial de un único qubit rotándolo con una puerta Hadamard, y luego lo rota de nuevo usando una puerta de fase para codificar una característica de dato .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Podemos visualizar la rotación en usando la función plot_Nstates que definimos.
plot_Nstates(states, axis=None, plot_trace_points=True)

El gráfico de la esfera de Bloch muestra la rotación en el eje Z donde . La flecha verde claro muestra el estado final.
La codificación por fase se usa en muchos mapeos de características cuánticos, en particular los mapeos de características y , y los mapeos de características de Pauli en general, entre otros.
Comprueba tu comprensión
Lee las preguntas a continuación, piensa tus respuestas y luego haz clic en los triángulos para ver las soluciones.
¿Cuántos qubits se necesitan para usar la codificación por fase descrita anteriormente y almacenar 8 características?
Respuesta: 8
Escribe código para el vector usando codificación por fase.
Respuesta:
Puede haber muchas respuestas. Aquí hay un ejemplo:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Codificación densa por ángulo
La codificación densa por ángulo (DAE, por sus siglas en inglés) es una combinación de codificación por ángulo y codificación por fase. La DAE permite codificar dos valores de características en un único qubit: uno con un ángulo de rotación en el eje Y, y el otro con un ángulo de rotación en el eje : . Codifica dos características de la siguiente manera:
Codificar dos características de datos en un qubit da como resultado una reducción de en el número de qubits necesarios para la codificación. Extendiendo esto a más características, el vector de datos puede codificarse como:
La DAE puede generalizarse a funciones arbitrarias de las dos características en lugar de las funciones sinusoidales usadas aquí. Esto se denomina codificación general de qubit[7].
Como ejemplo de DAE, el código siguiente codifica y visualiza la codificación de las características y .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Comprueba tu comprensión
Lee las preguntas a continuación, piensa tus respuestas y luego haz clic en los triángulos para ver las soluciones.
Según el tratamiento anterior, ¿cuántos qubits se necesitan para codificar 6 características usando codificación densa?
Respuesta: 3
Escribe código para cargar el vector usando codificación densa por ángulo.
Respuesta:
Nota que hemos rellenado la lista con un "0" para evitar el problema de tener un único parámetro sin usar en nuestro esquema de codificación.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Codificación con mapas de características incorporados
Codificación en puntos arbitrarios
La codificación por ángulo, la codificación por fase y la codificación densa preparaban estados producto con una característica codificada en cada qubit (o dos características por qubit). Esto es diferente de la codificación en base y la codificación en amplitud, ya que esos métodos hacen uso de estados entrelazados. No existe una correspondencia 1:1 entre una característica del dato y un qubit. En la codificación en amplitud, por ejemplo, una característica puede ser la amplitud del estado y otra característica puede ser la amplitud del estado . En general, los métodos que codifican en estados producto producen circuitos más superficiales y pueden almacenar 1 o 2 características en cada qubit. Los métodos que usan entrelazamiento y asocian una característica con un estado en lugar de con un qubit producen circuitos más profundos y pueden almacenar más características por qubit en promedio.
Sin embargo, la codificación no tiene que estar completamente en estados producto ni completamente en estados entrelazados como en la codificación en amplitud. De hecho, muchos esquemas de codificación incorporados en Qiskit permiten codificar tanto antes como después de una capa de entrelazamiento, en lugar de solo al principio. Esto se conoce como "re-carga de datos" (data reuploading). Para trabajo relacionado, consulta las referencias [5] y [6].
En esta sección, utilizaremos y visualizaremos algunos de los esquemas de codificación incorporados. Todos los métodos de esta sección codifican características como rotaciones en compuertas parametrizadas sobre qubits, donde . Ten en cuenta que maximizar la carga de datos para un número dado de qubits no es la única consideración. En muchos casos, la profundidad del circuito puede ser incluso más importante que la cantidad de qubits.
SU2 eficiente
Un ejemplo común y útil de codificación con entrelazamiento es el circuito efficient_su2 de Qiskit. De manera impresionante, este circuito puede, por ejemplo, codificar 8 características en solo 2 qubits. Veamos esto y luego tratemos de entender cómo es posible.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Al escribir nuestro estado, usaremos la convención de Qiskit en la que los qubits menos significativos se ordenan al extremo derecho, como en o Estos estados pueden volverse muy complicados rápidamente, y este raro ejemplo puede ayudar a explicar por qué dichos estados rara vez se escriben explícitamente.
Nuestro sistema comienza en el estado Hasta la primera barrera (un punto que etiquetamos ), nuestros estados son:
Eso es simplemente codificación densa, que ya hemos visto antes. Ahora, después de la compuerta CNOT, en la segunda barrera (), nuestro estado es
Ahora aplicamos el último conjunto de rotaciones de un solo qubit y agrupamos los estados semejantes para obtener:
Esto probablemente resulte demasiado complejo de analizar. En cambio, simplemente retrocede y piensa en cuántos parámetros hemos cargado en el estado: ocho. Pero tenemos solo cuatro estados de base computacional. A primera vista, puede parecer que hemos cargado más parámetros de lo que tiene sentido, ya que el estado final puede escribirse como . Sin embargo, ten en cuenta que ¡cada prefactor es complejo! Escrito así:
Se puede ver que sí tenemos ocho parámetros en el estado sobre los cuales codificar nuestras ocho características.
Al aumentar el número de qubits e incrementar el número de repeticiones de capas de entrelazamiento y rotación, se pueden codificar muchos más datos. Escribir las funciones de onda se vuelve rápidamente intratable. Pero aún podemos ver la codificación en acción.
Aquí codificamos el vector de datos con 12 características en un circuito efficient_su2 de 3 qubits, usando cada una de las compuertas parametrizadas para codificar una característica diferente.
En este vector de datos, las características se presentan en un orden particular. De forma aislada, no importa si se codifican en este orden o en el inverso. Lo importante es llevar el registro y ser consistente. Observa en el diagrama del circuito que efficient_su2 asume un cierto orden de codificación; específicamente, llena la primera capa de compuertas parametrizadas del qubit 0 al qubit 2, y luego pasa a la siguiente capa. Esto no es consistente ni inconsistente con la notación little-endian, ya que aquí las características de los datos no pueden ordenarse por qubit a priori, antes de especificar un circuito de codificación.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

En lugar de aumentar el número de qubits, podrías optar por incrementar el número de repeticiones de capas de entrelazamiento y rotación. Sin embargo, hay límites en cuántas repeticiones son útiles. Como se menciónó antes, existe una compensación: los circuitos con más qubits o más repeticiones de capas de entrelazamiento y rotación pueden almacenar más parámetros, pero lo hacen con una mayor profundidad de circuito. Volveremos a las profundidades de algunos mapas de características incorporados más adelante. Los siguientes métodos de codificación incorporados en Qiskit tienen "mapa de características" como parte de sus nombres. Recalquemos que codificar datos en un circuito cuántico es un mapeo de características, en el sentido de que lleva los datos a un nuevo espacio: el espacio de Hilbert de los qubits involucrados. La relación entre la dimensionalidad del espacio de características original y la del espacio de Hilbert dependerá del circuito que uses para la codificación.
Mapa de características
El mapa de características (ZFM, por sus siglas en inglés) puede interpretarse como una extensión natural de la codificación por fase. El ZFM consiste en capas alternadas de compuertas de un solo qubit: capas de compuertas Hadamard y capas de compuertas de fase. Sea el vector de datos con características. El circuito cuántico que realiza el mapeo de características se representa como un operador unitario que actúa sobre el estado inicial:
donde es el estado base de qubits. Esta notación se usa por coherencia con la referencia [4] de Havlicek et al. Las características del dato se mapean uno a uno con los qubits correspondientes. Por ejemplo, si tienes 8 características en un vector de datos, usarías 8 qubits. El circuito ZFM se compone de repeticiones de un subcircuito formado por capas de compuertas Hadamard y capas de compuertas de fase. Una capa Hadamard está formada por una compuerta Hadamard actuando sobre cada qubit en un registro de qubits, , dentro de la misma etapa del algoritmo. Esta descripción también aplica a una capa de compuertas de fase en la que el qubit es actuado por . Cada compuerta tiene una característica como argumento, pero la capa de compuertas de fase () es una función del vector de datos. El unitario completo del circuito ZFM con una sola repetición es:
Entonces repeticiones de este unitario serían
Las características se mapean a las compuertas de fase de la misma manera en todas las repeticiones. El estado del mapa de características ZFM es un estado producto y es eficiente para la simulación clásica[4].
Para comenzar con un ejemplo pequeño, se codifica un circuito ZFM de dos qubits usando Qiskit y se dibuja para mostrar la estructura simple del circuito. En el ejemplo, se implementa una sola repetición, , con el vector de datos . Ten en cuenta que esto está escrito en el orden estándar de un vector en Python, lo que significa que el elemento es Somos libres de codificar esta característica en nuestro qubit o en el Nuevamente, no siempre puede haber un único mapeo 1:1 del orden de características al orden de qubits, ya que diferentes mapas de características codifican distintas cantidades de características por qubit. Lo importante es que seamos conscientes de dónde se codifica cada característica. Al proporcionar una lista de parámetros al mapa de características , este codificará la característica 0 de la lista en el qubit menos significativo con una compuerta parametrizada, es decir, el qubit 0. Por lo tanto, seguiremos esa convención al hacerlo manualmente. Codificaremos en el qubit y en el qubit .
El operador unitario del circuito ZFM actúa sobre el estado inicial de la siguiente manera:
La fórmula se ha reorganizado alrededor del producto tensorial para enfatizar las operaciones en cada qubit. El siguiente código de Qiskit usa compuertas Hadamard y de fase explícitamente para mostrar la estructura del ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Ahora codificamos el mismo vector de datos en un circuito ZFM con tres repeticiones, , usando la clase z_feature_map de Qiskit, lo que en conjunto nos da el mapa de características cuántico . De forma predeterminada en la clase z_feature_map, los parámetros se multiplican por 2 antes de mapearse a la compuerta de fase . Para reproducir las mismas codificaciones que arriba, dividimos por 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Claramente este es un mapeo diferente al realizado manualmente arriba, pero observa la consistencia en el orden de parámetros: se codificó nuevamente en el qubit .
Puedes usar el ZFM mediante la clase ZFM de Qiskit; también puedes usar esta estructura como inspiración para construir tu propio mapeo de características.
Mapa de características
El mapa de características (ZZFM) extiende el ZFM con la inclusión de compuertas de entrelazamiento de dos qubits, específicamente la compuerta de rotación , . Se conjetura que el ZZFM es generalmente costoso de calcular en una computadora clásica, a diferencia del ZFM.
implementa una interacción y tiene entrelazamiento máximo para . puede descomponerse en una serie de compuertas sobre dos qubits, como se muestra en el siguiente código de Qiskit usando la compuerta RZZ y el método decompose de la clase QuantumCircuit. Codificamos una sola característica del vector de datos :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Como suele ocurrir, lo vemos representado como una sola unidad similar a una compuerta, hasta que usamos .decompose() para ver todas las compuertas constituyentes.
qc.decompose().draw("mpl", scale=1)

Los datos se mapean con una rotación de fase en el segundo qubit. La compuerta entrelaza los dos qubits sobre los que opera con un grado de entrelazamiento determinado por el valor de la característica codificada.
El circuito ZZFM completo consiste en una compuerta Hadamard y una compuerta de fase, como en el ZFM, seguidas del entrelazamiento descrito anteriormente. Una sola repetición del circuito ZZFM es:
donde contiene una capa de compuertas ZZ estructurada por un esquema de entrelazamiento. Varios esquemas de entrelazamiento se muestran en los bloques de código a continuación. La estructura de también incluye una función que combina las características de los datos de los qubits que se entrelazan de la siguiente manera. Supongamos que la compuerta se aplica a los qubits y . En la capa de fase, estos qubits tienen compuertas de fase que codifican y en ellos, respectivamente. El argumento de no será simplemente una de estas características u otra, sino una función que suele denotarse por (que no debe confundirse con el ángulo azimutal):
Veremos esto en varios ejemplos a continuación. La extensión a múltiples repeticiones es la misma que en el caso del z_feature_map:
A medida que los operadores han aumentado en complejidad, codifiquemos primero un vector de datos con un ZZFM de dos qubits y una repetición usando el siguiente código:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

De forma predeterminada en Qiskit, las características se mapean conjuntamente a mediante esta función de mapeo . Qiskit permite al usuario personalizar la función (o donde es el conjunto de pares de qubits acoplados mediante compuertas ) como un paso de preprocesamiento.
Pasando a un vector de datos de cuatro dimensiones y mapeando a un ZZFM de cuatro qubits con una repetición, podemos comenzar a ver el mapeo para varios pares de qubits. También podemos ver el significado del entrelazamiento "lineal":
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

En el esquema de entrelazamiento lineal, los pares de qubits vecinos más cercanos (numerados) en este circuito están entrelazados. Existen otros esquemas de entrelazamiento incorporados en Qiskit, incluyendo circular y full.
Mapa de características de Pauli
El mapa de características de Pauli (PFM, por sus siglas en inglés) es la generalización del ZFM y el ZZFM para usar compuertas de Pauli arbitrarias. El PFM tiene una forma muy similar a los dos mapas de características anteriores. Para repeticiones de la codificación de las características del vector
Para el PFM, se generaliza a un operador unitario de expansión de Pauli. Aquí presentamos una forma más generalizada de los mapas de características considerados hasta ahora:
donde es un operador de Pauli, . Aquí es el conjunto de todas las conectividades de qubits determinadas por el mapa de características, incluyendo el conjunto de qubits sobre los que actúan las compuertas de un solo qubit. Es decir, para un mapa de características en el que el qubit 0 fue actuado por una compuerta de fase, y los qubits 2 y 3 fueron actuados por una compuerta , el conjunto incluiría . recorre todos los elementos de ese conjunto. En los mapas de características anteriores, la función estaba involucrada ya sea exclusivamente con compuertas de un qubit o exclusivamente con compuertas de dos qubits. Aquí la definimos en general:
Para la documentación, consulta la documentación de la clase Pauli feature map de Qiskit). En el ZZFM, el operador está restringido a .
Una forma de entender el unitario anterior es mediante la analogía con el propagador en un sistema físico. El unitario anterior es un operador de evolución unitaria, , para un Hamiltoniano , similar al modelo de Ising, donde el parámetro de tiempo se reemplaza con valores de datos para impulsar la evolución. La expansión de este operador unitario da el circuito PFM. Las conectividades de entrelazamiento en pueden interpretarse como acoplamientos de Ising en una red de espines.
Consideremos un ejemplo de los operadores de Pauli y que representan esas interacciones de tipo Ising. Qiskit proporciona una clase pauli_feature_map para instanciar un PFM con una elección de compuertas de un qubit y qubits, que en este ejemplo se pasarán como cadenas de Pauli 'Y' y 'XX'. Típicamente, es 1 o 2 para interacciones de un qubit y dos qubits, respectivamente. El esquema de entrelazamiento es "lineal", lo que significa que solo los qubits vecinos más cercanos en el circuito cuántico están acoplados. Ten en cuenta que esto no corresponde a qubits vecinos más cercanos en la computadora cuántica en sí, ya que este circuito cuántico es una capa de abstracción.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit proporciona un parámetro en los mapas de características de Pauli para controlar la escala de las rotaciones de Pauli.
El valor predeterminado de es . Optimizando su valor en el intervalo, por ejemplo, se puede alinear mejor un núcleo cuántico con los datos.
Galería de mapas de características de Pauli
Aquí visualizamos varios mapas de características de Pauli para circuitos de dos qubits para tener una mejor imagen del rango de posibilidades.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Lo anterior puede, por supuesto, extenderse para incluir otras permutaciones y repeticiones de matrices de Pauli. Se anima a quienes estudian este material a experimentar con esas opciones.
Revisión de los mapas de características incorporados
Has visto varios esquemas para codificar datos en un circuito cuántico:
- Codificación en base
- Codificación en amplitud
- Codificación por ángulo
- Codificación por fase
- Codificación densa
Has visto cómo construir tus propios mapas de características usando estos esquemas de codificación, y has visto cuatro mapas de características incorporados que aprovechan la codificación por ángulo y por fase:
- SU2 eficiente
- Mapa de características Z
- Mapa de características ZZ
- Mapa de características de Pauli
Estos mapas de características incorporados se diferenciaron entre sí en varios aspectos:
- La profundidad para un número dado de características codificadas
- La cantidad de qubits requeridos para un número dado de características
- El grado de entrelazamiento (obviamente relacionado con las otras diferencias)
El código a continuación aplica estos cuatro mapas de características incorporados a la codificación de un conjunto de características y grafica la profundidad de dos qubits del circuito resultante. Dado que las tasas de error de dos qubits son mucho más altas que las de compuertas de un solo qubit, podría ser razonable estar más interesado en la profundidad de las compuertas de dos qubits. En el código siguiente, obtenemos conteos de todas las compuertas en un circuito descomponiendo primero el circuito y luego usando count_ops(), como se muestra a continuación. Aquí las compuertas de dos qubits que nos interesan son las compuertas 'cx':
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
En general, los mapas de características de Pauli y ZZ resultarán en mayor profundidad de circuito y mayor número de compuertas de 2 qubits que efficient_su2 y los mapas de características Z.
Dado que los mapas de características incorporados en Qiskit son ampliamente aplicables, a menudo no necesitaremos diseñar los nuestros propios, especialmente en la fase de aprendizaje. Sin embargo, los expertos en aprendizaje automático cuántico probablemente volverán al tema del diseño de su propio mapeo de características a medida que enfrenten dos desafíos complejos:
-
Hardware moderno: la presencia de ruido y la gran sobrecarga de los códigos de corrección de errores significa que las aplicaciones actuales necesitarán considerar cosas como la eficiencia del hardware y la minimización de la profundidad de las compuertas de dos qubits.
-
Mapeos que se adapten al problema en cuestión: Una cosa es decir que el
zz_feature_map, por ejemplo, es difícil de simular clásicamente y, por lo tanto, interesante. Otra muy diferente es que elzz_feature_mapsea idealmente adecuado para tu tarea de aprendizaje automático o conjunto de datos. El rendimiento de diferentes circuitos cuánticos parametrizados en diferentes tipos de datos es un área activa de investigación.
Cerramos con una nota sobre la eficiencia del hardware.
Mapeo de características eficiente en hardware
Un mapeo de características eficiente en hardware es aquel que tiene en cuenta las restricciones de las computadoras cuánticas reales, con el objetivo de reducir el ruido y los errores en el cómputo. Al ejecutar circuitos cuánticos en computadoras cuánticas de corto plazo (near-term), existen muchas estrategias para mitigar el ruido inherente al hardware. Una estrategia principal para la eficiencia en hardware es la minimización de la profundidad del circuito cuántico, de modo que el ruido y la decoherencia tengan menos tiempo para corromper el cómputo. La profundidad de un circuito cuántico es el número de pasos de compuertas alineados en el tiempo requeridos para completar todo el cómputo (después de la optimización del circuito)[5]. Recuerda que la profundidad del circuito lógico abstracto puede ser mucho menor que la profundidad una vez que el circuito es transpilado para una computadora cuántica real.
La transpilación es el proceso de convertir el circuito cuántico de una abstracción de alto nivel a uno listo para ejecutarse en una computadora cuántica real, teniendo en cuenta las restricciones del hardware. Una computadora cuántica tiene un conjunto nativo de compuertas de uno y dos qubits. Esto significa que todas las compuertas en el código de Qiskit deben transpilarse al conjunto de compuertas nativas del hardware. Por ejemplo, en ibm_torino, una QPU con un procesador Heron r1 completada en 2023, las compuertas nativas o de base son {CZ, ID, RZ, SX, X}. Estas son la compuerta de dos qubits Z controlada, y compuertas de un qubit llamadas identidad, rotación , raíz cuadrada de NOT y NOT, respectivamente, proporcionando un conjunto universal. Al implementar compuertas de múltiples qubits como un subcircuito equivalente, se requieren compuertas físicas de dos qubits, junto con otras compuertas de un qubit disponibles en el hardware. Además, para realizar una compuerta de dos qubits en un par de qubits que no están físicamente acoplados, se agregan compuertas SWAP para mover los estados de los qubits entre qubits para habilitar el acoplamiento, lo que genera una extensión inevitable del circuito. Usando el argumento optimization que puede configurarse desde 0 hasta un nivel máximo de 3. Para mayor control y personalización, el flujo de transpilación puede gestionarse con el Qiskit Pass Manager. Consulta la documentación del Transpiler de Qiskit para más información sobre la transpilación.
En Havlicek et al. 2019 [2], una de las formas en que los autores logran eficiencia en hardware es usando el mapa de características porque es una expansión de segundo orden (consulta la sección "Mapa de características " arriba). Una expansión de orden tiene compuertas de qubits. Las computadoras cuánticas de IBM® no tienen compuertas nativas de qubits, donde , por lo que implementarlas requeriría descomposición en compuertas CNOT de dos qubits disponibles en el hardware. Una segunda forma en que los autores minimizan la profundidad es eligiendo una topología de acoplamiento que se mapee directamente a los acoplamientos de la arquitectura. Una optimización adicional que realizan es apuntar a un subcircuito de hardware de alto rendimiento y conectividad adecuada. Otras cosas a considerar son minimizar el número de repeticiones del mapa de características y elegir un esquema de entrelazamiento personalizado de baja profundidad o "lineal" en lugar del esquema "completo" que entrelaza todos los qubits.

El gráfico anterior muestra una red de nodos y aristas que representan qubits físicos y acoplamientos del hardware, respectivamente. Se muestra el mapa de acoplamiento y el rendimiento de ibm_torino con todas las posibles compuertas de acoplamiento CZ de dos qubits. Los qubits están codificados por colores en una escala basada en el tiempo de relajación T1 en microsegundos (μs), donde tiempos T1 más largos son mejores y se muestran en un tono más claro. Las aristas de acoplamiento están codificadas por colores según el error de CZ, donde los tonos más oscuros son mejores. La información sobre la especificación del hardware se puede acceder en el esquema de configuración del backend del hardware IBMQBackend.configuration().
Referencias
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()